Using Python Tesseract OCR to Read Scanned PDFs and Build a Custom GPT Knowledge Base
Topic: ai
Summary: In this tutorial, I show how to use Python and Tesseract OCR to convert scanned PDF documents into readable text that can be used to build a custom GPT knowledge base. Many older documents—like condo bylaws or legal records—were scanned decades ago and aren't searchable because they contain images, not text. I walk through how to extract text from these image-based PDFs using pdf2image and pytesseract, saving the output to a .txt file with clearly defined document boundaries. That text file is then uploaded to a custom GPT using OpenAI's GPT Builder, allowing you to ask natural language questions like “What’s the pet policy?” or “How many cars can I park?”—without reading hundreds of pages. The process includes setting up input and output folders, configuring environmental variables for Tesseract and Poppler, and ensuring that the script is beginner-friendly with comments and versioned outputs. This workflow is perfect for anyone dealing with legacy PDFs in real estate, legal, or research contexts. It dramatically reduces time spent digging through unsearchable documents and makes that data easily accessible via conversational AI. All files, code, and setup details are available in the video description.
If you're working with old PDF documents—especially scanned real estate files or legal records—you've likely run into a common frustration: you can't search or copy the text. These PDFs aren't OCR-processed, meaning the text is embedded in images, not selectable or machine-readable. This tutorial solves that problem by using Python and Tesseract OCR to extract the text and build a custom GPT knowledge base that you can query conversationally.
📺 Watch the full tutorial: https://youtu.be/jyDNRwZf6p8?si=U3qkU6TLCkVqvwF6
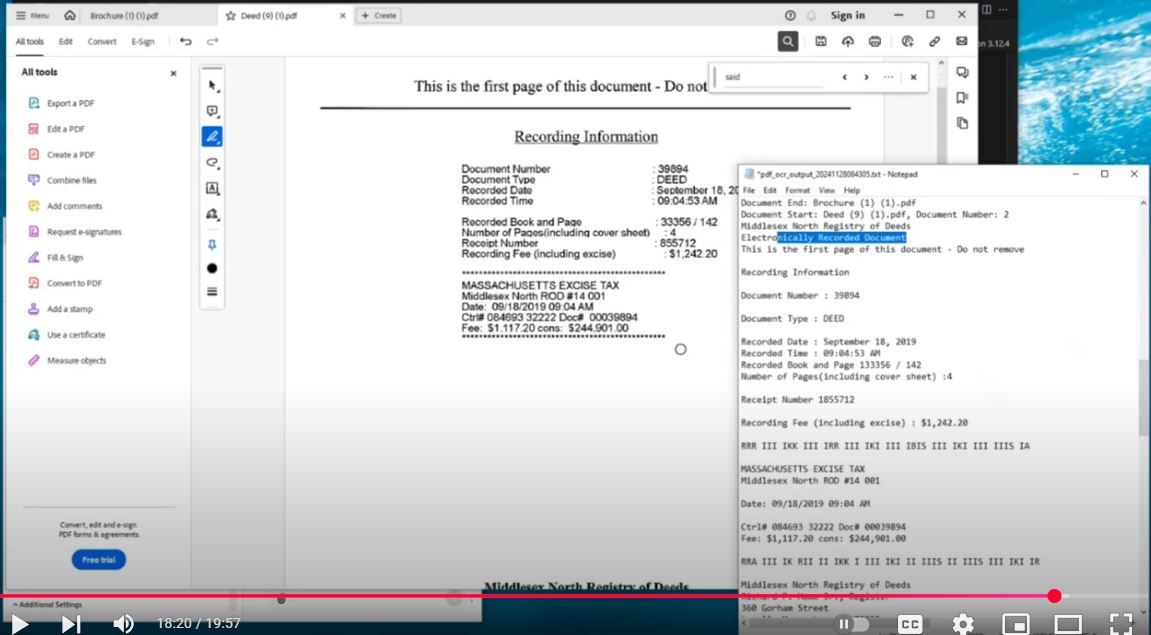
Why You Need OCR for GPT
Imagine buying a condo and receiving a 300-page stack of scanned PDFs covering all the rules and regulations—pet policies, parking restrictions, rental terms. These documents are often decades old, scanned in the 1970s–1990s, and impossible to search efficiently.
In this tutorial, I show how to use Tesseract OCR to convert those unreadable PDFs into structured text. Then, I demonstrate how to upload the resulting text file into a custom GPT so you can ask questions like:
- “Am I allowed to have a 50lb dog in this condo?”
- “How many cars can I park here?”
This approach makes it easy to extract useful, actionable information from hundreds of pages of scanned material—without manually reading it all.
Step-by-Step Process
1. Prove the PDFs Aren’t OCR’d
I start by trying to search for a word in the PDF viewer. Even though the word appears visibly, the search fails—confirming the file is image-only.
2. Ask Questions of the Custom GPT
I demonstrate asking questions of a GPT trained on this document. It accurately responds with specific rules and citations, showing the power of this pipeline once the OCR is complete.
3. Use Python to OCR the Files
The core of the tutorial involves running a Python script that:
- Converts PDFs to images using
pdf2image - Extracts text from those images with
pytesseract - Outputs a
.txtfile with all OCR-processed content - Organizes documents with clearly marked
Document StartandDocument Endtags
This structure makes it easy for GPT to identify and respond using the correct context.
4. Upload the Text to a Custom GPT
Using OpenAI’s GPT Builder (available to ChatGPT Plus users), I walk through:
- Naming the GPT
- Writing a tailored prompt
- Adding a sample conversation starter
- Uploading the
.txtfile as the knowledge base - Making the GPT shareable with family, realtors, or anyone with the link
Handling Legacy Documents
OCR performance depends on the quality of the scans:
- A clean 1992 scan processes in seconds
- A degraded 1975 document may take hours
In cases where OCR accuracy is poor, preprocessing steps (like noise reduction using OpenCV or PIL) can help. This is beyond the scope of the video but worth exploring if you're working with highly degraded files.
Script Features and Tips
- File Management: Input PDFs go in an
input_filesfolder; output text goes tooutput_files. - Versioning: Files are timestamped to the second to avoid overwrites and keep version history.
- Environment Setup: Uses a
.envfile to configure paths for Tesseract and Poppler dependencies, avoiding Windows path issues. - Beginner-Friendly Comments: The script is heavily commented using GPT-generated explanations so it’s easy to follow and adapt.
Conclusion
By combining OCR with a custom GPT, you unlock a powerful way to interact with legacy documents. This is especially valuable in real estate, legal, and historical research contexts where manual review of large, unstructured files is impractical.
👉 Watch the video here
📎 All code and resources are linked in the description.


